Multi-Agenten-Systeme
Ich habe im letzten Jahr an mehrereh KI-Agenten in verschiedenen Orgranisationen geareitet - von Startups zu Enterprises. Und im Grunde war die Problemstellung immer die gleiche: ChatGPT weiß zwar sehr viel, aber es kann dir nicht sagen, wie viele Leads du letzten Monat hattest oder wie der Lieferstatus dieser Bestellungen ist.
Die Lösung ist, ein Mulit-Agenten-System zu entwickeln, das mit den verschiedenen Datenquellen des Unternehmens kommuniziert und das ganze per Chat-Interface verfügbar macht.
Das ganze könnte zum Beispiel so aussehen:
Über eine Chat-UI stellt der Nutzer eine Frage. Diese Fragen wird dann ans Backend weitergeleitet. Dort gibt es wiederrum mehrere Agenten, die auf verschiedenen Bereiche spezialisiert sind. Ein Agent ist zum Beispiel darauf spezialisiert, SQL-Abfragen zu machen, ein anderer darauf, die Daten als Charts zu visualisieren usw. Außerdem gibt es einen Orchestrierungs-Agenten, der die einzelnen Agenten überwacht und Aufgaben verteilt. Am Ende wird aus den Ouputs aller Agenten eine Antwort generiert, die an den Client zurückgeschickt wird.
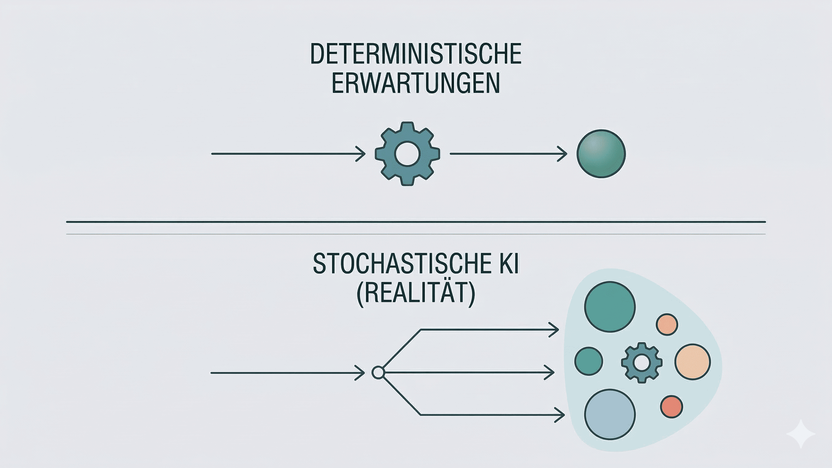
Die stochastische Natur von LLMs
LLMs sind stochastich “by design”. Sie sind darauf ausgelegt, bei der gleichen Frage jedes Mal leicht unterschiedliche Antworten zu geben. Sie sind “Token Guesser”, die versuchen mit statistischen Modellen herauszufinden, was der wahrscheinlich sinnvollste nächste Token ist basierend auf den bisherigen Token. Und da gibt es immer Spielraum.
Und wenn man jetzt ein Multi-Agenten-System verwendet, das mehrere LLM-Abfragen hintereinander kettet, können sich diese kleinen Abweichungen natürlich potenzieren.
Aber das beißt sich oft mit den Erwartungen der Endnutzer, die deterministische Antworten erwarten.
Fallbeispiel
Nehmen wir zum Beispiel ein Tool, über das Nutzer Dinge fragen können wie “Wie waren meine Leads in den letzten 3 Monaten?”. Das Programm zapft dann die relevanten Datenquellen an und visualisiert das Resultat in einem hübschen Dashboard mit Charts. So weit, so gut. Nun fragt der Nutzer aber beim nächsten Mal die gleiche Frage - und dieses Mal sieht das Dashboard ein bisschen anders aus. Oder die Daten sind dieses Mal nach Kanälen aufgeschlüsselt anstatt aggregiert. Aber der Nutzer kritisiert dann: “Wenn ich nach den Leads frage, will ich immer exakt dieses Dashboard haben”. Er erwartet also eine deterministische Antwort.
Das Spannungsfeld: Deterministische Erwartungen vs. Stochastische Natur
Das Beispiel von oben zeigt, dass Erwartungen an das System gestellt werden, die dessen Natur widersprechen.
Außerdem wollen wir Nutzer kein “ChatGPT mit internen Infos”, sondern sie wollen einen Ersatz für PowerBI.
Die Lösung
Der erste Ansatz ist meist, die Prompts immer weiter mit Guardrails und Use-Case spezifischen Beispielen aufzublähen. Aber das versagt meist recht schnell.
Stand März 2026 läuft es früher oder später darauf hinaus, auf einen Skill-basierten Ansatz zu wechseln. Eine gute Einführung zum Thema Skills findet man hier. Aber die Grundlegende Idee ist dann, für jeden Prompt, der eine deterministische Antwort braucht, einen SKill mit detaillierten Instruktionen zu erstellen.
Ist das die entgültige, perfekte Lösung? Wohl kaum. Aber zum jetztigen Zeitpunkt ist es der einzige Weg, die Anforderungen der Nutzer mit der Natur der LLMs zu vereinbaren.